
并发创建虚拟机是云计算最常见的应用场景之一,几乎所有的云计算厂商都有相对成熟的凯发k8国际首页登录的解决方案,可以支持数百规模的虚拟机并发创建。然而当并发规模突破1000量级后,确保虚拟机100%成功创建的难度急剧增加,仅有少数厂商的产品能够达到这一水平。
在浪潮基于openstack rocky版本进行的全球最大规模单一集群测试中,浪潮云海incloud openstack 5.6(icos5.6)成功完成了100%并发创建2000虚拟机的极限挑战,其首创的分布式锁方案很好地解决了由于neutron(openstack网络组件)瓶颈导致的ip地址冲突问题。
ip地址冲突导致并发创建800虚拟机失败
本次大规模测试过程中,进行并发创建800虚拟机时发现总有失败出现,不能达到100%的成功率,查看nova(openstack核心组件,负责管理和维护计算资源)日志发现如图1所示。

图1 并发创建800虚拟机失败提示
neutron日志也报错,如图2所示。

图2 neutron日志报错提示
在对neutron分配ip机制进行深入研究后,icos网络团队发现原生社区分配ip设计存在缺陷,无锁设计必然导致ip分配产生冲突。冲突产生的根源在于并发情况下同时读取ipam_allocate表并分配可用ip(分配完成后并不立即commit到数据库),会大概率导致ip冲突,同时由于create_port_db封装方式,会将创建port、创建可用ip、可用ip保存到ips表,这三个事务共同commit,进一步加剧了冲突概率。分析如图3所示。
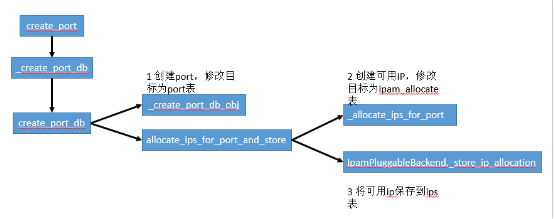
图3 无锁设计导致ip分配产生冲突
针对这一问题,社区提供的凯发k8国际首页登录的解决方案是为create_port增加retry装饰器,一旦监测到提交数据库失败后重新执行create_port来解决冲突,其默认休息0.1秒,最大重试10次。不过,在并发规模过大时,由于间隔较短且重试次数偏少,很容易出现retry次数耗尽也无法成功创建虚拟机的情况,浪潮在并发创建800虚拟机出现失败的原因即在于此。
寻找最优解 独创分布式锁方案
经历并发创建800虚拟机失败后,icos网络团队尝试增加retry重试次数并加长重试间隔,将设置调整为重试次数20,间隔0.5秒,实现了并发创建800 虚拟机成功,如图4所示。
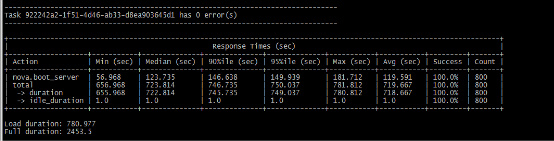
图4 成功并发创建800 虚拟机
但这一优化方案并非最优解,次数增加与间隔延长带来的通信开销与cpu资源占用严重:大批量创建虚拟机,创建端口时间有概率增长,理论最坏情况为[0.5, 1, 2, 4, 8, 10, 10, ... 10] 共165.5秒,需要延长nova等待vf_plugged时间,与此同时由于最大重试20次,期间neutron server异常繁忙,占用大量cpu资源。
摆在icos网络团队面前的问题是,如果800并发就产生如此高的资源占用,那么在2000并发的情况下,平台性能是否足以支撑100%的成功率?有没有更好的优化方案?最终,icos网络团队开发了分布式锁方案,成功完成了并发创建2000虚拟机。
浪潮独创的分布式锁方案采用了新的ipam_dlm驱动,引入openstack tooz项目,基于原有的ip分配算法对分配ip过程增加分布式锁,解决ip分配冲突。
解决ip地址分配冲突问题与酒店办理入住的场景非常相似,假设有10名前台负责同时到店的800位客人入住,retry的机制是前台仅负责随机分配房卡,由客人自行前往确认该房间是否可以入住,若已有人入住则返回前台重新分配新房间;而分布式锁方案的机制则是所有前台临时共享一个独立数据库,基于“先到先得”原则,任一房间一旦在数据库中已经登记则自动锁定,确保了每位领到房卡的客人一定可以入住该房间。
ipam_dlm设计序列图如图5所示。
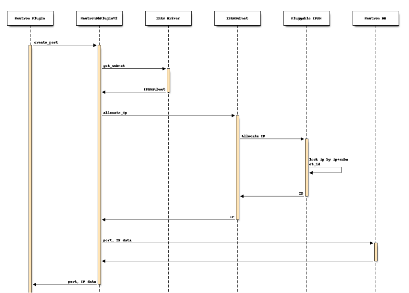
图5 ipam_dlm设计序列图
在更新neutron代码后,采用etcd作为分布式锁后端,重新测试并发创建800虚拟机的平均时长相比优化后的retry方案减少了18秒,load duration时间大幅缩短。如图6所示。
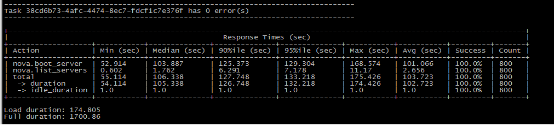
图6 icos分布式锁方案效果
目前,浪潮已经将分布式锁凯发k8国际首页登录的解决方案作为bp提交社区,并且得到社区的认可(bp已合入)。随后,浪潮将正式向社区提交代码。





